Zugriff auf die eigene Datenbank und das Archiv: KI ans Firmenwissen anschliessen?
Was grosse Unternehmen schon länger können, ist nun auch für kleinere Büros möglich: der KI-Zugriff auf den eigenen Server und die eigenen Dokumente. Doch ist es wirklich die richtige Strategie, das gesamte Wissen einfach anzuschliessen?
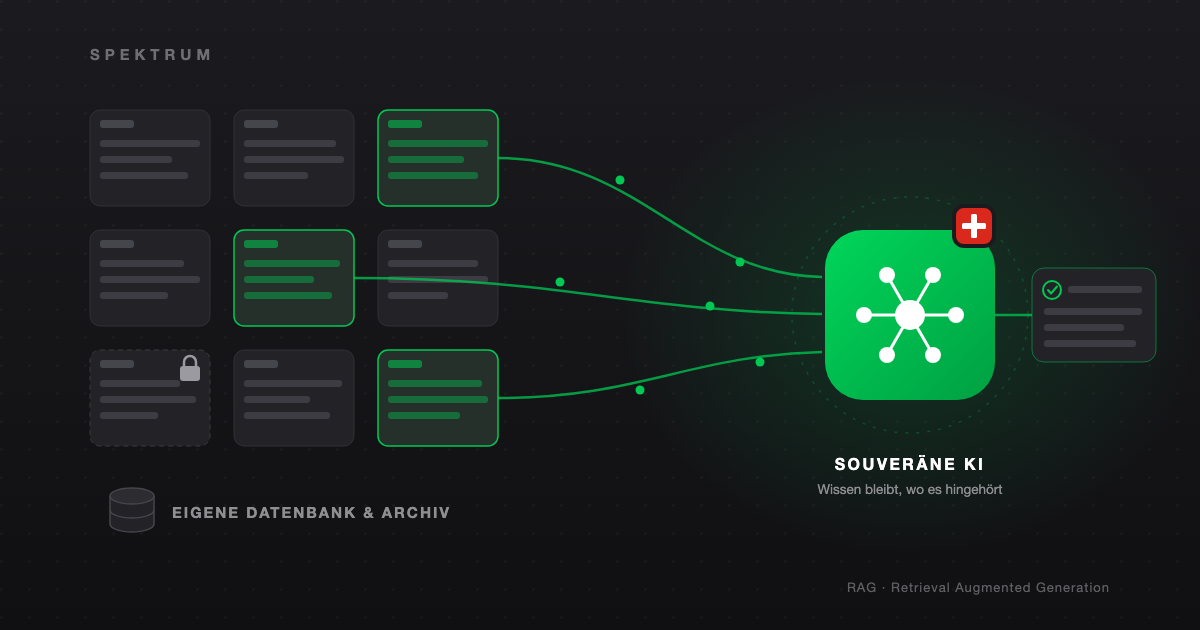
Was jetzt möglich ist
Microsoft, Google, Perplexity und Anthropic (Claude) bieten heute alle Schnittstellen an, mit denen sich das gesamte Firmenwissen – Projektablagen, E-Mails, Berichte, Pläne – an einen KI-Assistenten anschliessen lässt. Was vor Kurzem noch Konzernen mit eigenen IT-Abteilungen vorbehalten war, ist damit auch für kleinere Büros erreichbar geworden: Der KI-Assistent beantwortet Fragen direkt aus dem eigenen Archiv, findet den Bericht von vor drei Jahren und fasst die Korrespondenz zu einem Projekt zusammen.
Für Planungsbüros, Verwaltungen und KMU ist das verlockend – das institutionelle Wissen, das in Ordnerstrukturen und Postfächern schlummert, wird plötzlich abfragbar.
Die Technik dahinter: Retrieval Augmented Generation
Technisch steckt hinter diesen Angeboten meist Retrieval Augmented Generation (RAG): Das Sprachmodell wird mit einer Suche über die eigenen Dokumente kombiniert. Stellt jemand eine Frage, sucht das System zuerst die relevanten Passagen aus dem Archiv heraus und gibt sie dem Modell als Kontext mit. Die Antwort basiert damit auf den eigenen Unterlagen – ohne teures Training eines eigenen Modells.
Das Fraunhofer IESE erklärt das Verfahren verständlich, und das Mittelstand-Digital Zentrum Chemnitz zeigt, was damit für KMU konkret möglich wird – vom Kundenservice bis zur Angebotserstellung.
Doch ist es wirklich die richtige Strategie, das gesamte Wissen einfach anzuschliessen? Zwei Punkte stimmen mich nachdenklich.
Erster Vorbehalt: Wer alles anschliesst, deckt die eigene Datenordnung auf
Wer alles anschliesst, deckt schonungslos auf, wie es um die eigene Datenordnung steht. Beim Microsoft Copilot zeigt sich das exemplarisch: Die KI durchsucht alles, worauf eine Person Zugriff hat. Falsch gesetzte Berechtigungen, die jahrelang niemandem auffielen, werden plötzlich sichtbar.
Die Zahlen dazu sind ernüchternd: Eine Analyse beziffert, dass in typischen Umgebungen rund 45 Prozent der Dokumente gar nicht klassifiziert sind, und eine Untersuchung von Concentric AI kam zum Schluss, dass 83 Prozent der sensiblen Daten intern breiter geteilt werden als vorgesehen. Eine datenschutzrechtliche Einordnung liefert Dr. Datenschutz.
Die KI erfindet das Berechtigungsproblem nicht – sie macht es nur sichtbar. Was vorher in der Tiefe der Ordnerstruktur verborgen war, ist plötzlich eine Suchanfrage entfernt.
Zweiter Vorbehalt: die Abhängigkeit
Wer sein Wissen tief in eine Plattform integriert, bindet sich strategisch – der Lock-in entsteht weniger durch das KI-Modell selbst als durch das gesamte Ökosystem drumherum. Indexierte Dokumente, eingespielte Workflows, geschulte Mitarbeitende: Je tiefer die Integration, desto teurer der Ausstieg.
Oder pointiert formuliert: Wer seine Daten nicht flexibel bewegen kann, besitzt sie nur theoretisch. Kein Wunder, suchen immer mehr Unternehmen aktiv nach europäischen Alternativen.
Dass es auch anders geht, zeigt ausgerechnet die Schweiz
Mit Apertus haben ETH Zürich, EPFL und das CSCS ein vollständig offenes Sprachmodell veröffentlicht – Architektur, Gewichte und Trainingsdaten sind frei zugänglich, und das Modell beherrscht sogar Schweizerdeutsch.
Über Schweizer Anbieter ist es inzwischen als durchgängig souveräne Lösung verfügbar: vom Modell über das Hosting bis zur Schnittstelle bleibt alles in der Schweiz. Wer sein Firmenwissen an eine KI anschliessen will, muss sich also nicht zwingend an ein US-Ökosystem binden.
Mein Fazit: nicht «ob», sondern «in welcher Reihenfolge»
Die Frage ist nicht «anschliessen oder nicht», sondern «in welcher Reihenfolge»:
- Zuerst Ordnung schaffen: Datenablage und Berechtigungen bereinigen, bevor eine KI sie durchsuchbar macht. Was die KI findet, sollte gefunden werden dürfen.
- Dann bewusst entscheiden: Nicht das gesamte Archiv pauschal anschliessen, sondern gezielt festlegen, welches Wissen an welche Lösung angebunden wird.
- Den Ausstieg offenhalten: Lösungen bevorzugen, bei denen Daten und Index portabel bleiben – und den Weg zu einer unabhängigen Alternative wie Apertus nicht verbauen.
Genau hier setzen wir mit unseren Tools an: Schweizer Lösungen, bei denen das Wissen dort bleibt, wo es hingehört – bei Ihnen.
Erst Ordnung, dann Anschluss – und immer mit offenem Rückweg. Wer diese Reihenfolge einhält, nutzt die neuen Möglichkeiten, ohne die Kontrolle über das eigene Wissen abzugeben.
Häufige Fragen

Raumplaner & KI-Berater · SPEKTRUM · ETH Zürich · LinkedIn
SPEKTRUM Angebot
KI-Beratung für Büros und Verwaltungen
Wir begleiten Sie von der Datenordnung über die Anbieterwahl bis zur souveränen Schweizer Lösung – pragmatisch, unabhängig und ohne Lock-in.
Mehr erfahren →Verwandte Artikel
Apertus: Souveräne KI für die Verwaltung
Wie das Ticino amtliche Dokumente mit einem Open-Source-LLM übersetzt – lokal, datenschutzkonform, ohne Cloud.
Artikel lesen →KI-Agenten für Ihr Büro
Das 30-Tage-Playbook für KMU – strukturiert, ohne Hype, mit konkreten Schritten für den Einstieg.
Artikel lesen →Das richtige LLM ist entscheidend
Nicht jedes Sprachmodell eignet sich für jede Aufgabe – warum die Modellwahl über Erfolg oder Misserfolg entscheidet.
Artikel lesen →